
Já pararam para pensar como o GPT funciona? Como diriam os vendedores da tekpix, não é magia, é tecnologia. Segue uma breve introdução a seguir.
Processamento de Linguagem Natural (PLN) é uma sub área da inteligência artificial focada em permitir que computadores entendam, interpretem e gerem linguagem humana de forma útil e significativa. Ele abrange uma variedade de tecnologias que transformam linguagem natural em dados estruturados e vice-versa, permitindo que máquinas realizem tarefas como tradução automática, resposta a perguntas, reconhecimento de fala, e interação em linguagem natural. Pensem, simplificadamente no chat GPT e afins (bard, gemini, lhama…) como um “autocompletador” de palavras, tal como a maioria dos celulares possuem, porém com muito mais parâmetros e robustez.
É PLN, mas poderia chamar de estatística aplicado a predição de palavras.
O Processamento de Linguagem Natural, em sua essência, utiliza métodos estatísticos para entender e gerar linguagem humana. Esses métodos permitem que os computadores não apenas reconheçam palavras, mas também prevejam qual palavra é a mais provável que venha a seguir em uma frase, ou qual palavra ou frase melhor completa uma em determinada sentença.
Imagine o PLN como um meteorologista tentando prever o clima. Assim como meteorologistas usam dados históricos sobre o clima para prever condições futuras, sistemas de PLN usam grandes quantidades de texto para aprender como as palavras são comumente usadas e organizadas. Essa aprendizagem é essencialmente estatística: o sistema analisa frequências e padrões no uso de palavras para fazer previsões sobre quais tendem a aparecer juntas ou em sequências específicas.
Porém, sabemos que não podemos predizer o futuro apenas com dados passados. Aí reside uma das limitações do PNL. A originalidade do texto é estatística e baseada nos dados anteriores. Exemplo: Analisando os discursos do Bolsonaro, a probabilidade de ele falar “tocante” após ele falar “neste” é alta. A probabilidade de vir um absurdo na sequência é 99,99%, mas não chega a 100%, mas divago. Portanto, ao considerar o PLN como estatística aplicada à predição de palavras, temos uma visão clara de como essa tecnologia opera sob a superfície: ela calcula o uso probabilístico das palavras para gerar previsões linguísticas precisas. E para tal, é necessário o uso de redes neurais.
O Processamento de Linguagem Natural (PLN) é uma categoria de inteligência artificial (IA), mas se analisarmos profundamente o significado dos termos, notaremos que o PLN, estritamente falando, não exerce inteligência própria – ele opera com base em métodos estatísticos. Além disso, não é completamente artificial, pois é desenvolvido e treinado utilizando dados criados – ou tiveram interferência – por seres humanos.
E as redes neurais? O que tem a ver com isso ?
Redes neurais são modelos computacionais inspirados no funcionamento do cérebro humano, projetadoa para reconhecer padrões de maneira similar às redes de neurônios biológicos. Imagine uma rede neural como uma equipe complexa de analistas: cada “neurônio” na rede analisa uma pequena parte das informações, passa suas conclusões para a próxima camada da rede, e assim por diante, até que uma conclusão final seja alcançada. Esse processo permite que a rede aprenda e tome decisões a partir de exemplos de dados, ajustando suas conexões internas, conhecidas como pesos, para melhorar seu desempenho ao longo do tempo.
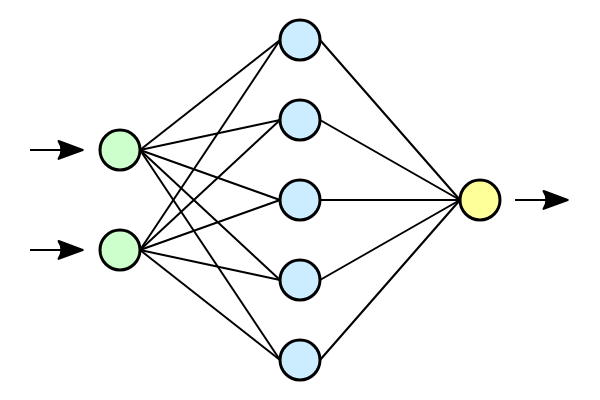
fonte: wikipedia
Pode-se comparar o uso de redes neurais em PLN a um tradutor habilidoso que, ao invés de aprender múltiplas línguas através de livros de regras gramaticais, aprende através da imersão em enormes quantidades de diálogos e textos. Esse “tradutor” ajusta continuamente suas técnicas de tradução com base no que funciona melhor na prática, o que é essencialmente o que uma rede neural faz: ajusta-se para produzir as traduções ou respostas mais precisas e naturais possíveis, baseadas no contexto e nos dados que recebe.
Um outro exemplo: escrever um algorítimo que reconheça um gato é algo muito complexo .O que caracteriza um gato? Como traduzir isto para um algorítimo? E se a imagem do gato estiver de costas, por exemplo? Ao invés disso, podemos usar redes neurais e alimentamos elas com milhares de fotos de gatos. Essas redes, então, aprendem a identificar padrões e características que definem o que é o bichano como a forma dos olhos, a textura da pelagem, e o contorno das orelhas. Ao analisar cada imagem, a rede neural ajusta seus pesos internos — que são parâmetros que influenciam a decisão do modelo — de modo que a cada nova foto analisada, ela fica progressivamente melhor em reconhecer gatos. Este processo é conhecido como treinamento. Ao final do treinamento, a rede neural desenvolveu uma ‘intuição’ para detectar gatos, baseada não em regras explícitas programadas por humanos, mas sim em exemplos concretos que ela aprendeu a interpretar.

Fonte: mega curioso.
Conceitos Fundamentais do PLN
Eis alguns conceitos básicos que aparecem quando falamos de PLN:
Tokens: No PLN, tokens são as unidades básicas de texto, semelhantes a palavras em uma frase. Por exemplo, a frase “O gato está dormindo.” seria dividida em tokens como “O”, “gato”, “está”, “dormindo” e “.”.
Parâmetros: No contexto de modelos de PLN, parâmetros são valores numéricos ajustáveis que o modelo usa para fazer previsões. Eles são ajustados durante o treinamento do modelo para melhor capturar as características do idioma que está sendo modelado.
Alucinações: Este termo é usado para descrever situações em que um modelo de PLN gera informações que não são suportadas pelos dados de entrada ou pela realidade. Por exemplo, um modelo pode “alucinar” detalhes em uma tradução que não existem no texto original. Imagine o PLN como um aprendiz de chef tentando aprender receitas de diferentes culturas apenas lendo livros de receitas em diversos idiomas. Os “tokens” são os ingredientes individuais, enquanto os “parâmetros” são as técnicas culinárias que o aprendiz ajusta para melhorar suas habilidades. As “alucinações” aconteceriam se o aprendiz, ao tentar recriar uma receita, adicionasse ingredientes que nunca foram mencionados no livro de receitas original.